28/05/2025Claude 4 ricatta le persone: cosa è successo davvero?
Nei giorni scorsi è girata sul web questa notizia che affermava che la nuova AI di Anthropic “ricatta e inganna”.
Ma non è quello che è successo.
E volevo chiarire meglio questa faccenda. 🙌
Facciamo prima un passo indietro, perché volevo darti modo di avere tutto il contesto, sia raccontandoti dei nuovi modelli di Anthropic che parlandoti di questa notizia.
Settimana scorsa, Anthropic ha rilasciato Claude Opus 4 e Claude Sonnet 4.

E sembra che, ad oggi, siano i modelli migliori per il Coding, il reasoning avanzato e per lo sviluppo di Agenti AI.

Perché ho sottolineato “sembra” sopra?
Perché è chiaro che tutte le Big Tech vogliono avere il modello migliore.
E trovano sempre il modo, a livello comunicativo, di farlo sapere a tutti.
A dir la verità, per quanto riguarda il coding, sembra che i nuovi modelli di Anthropic siano davvero i migliori.
Invece, per usi standard come scrittura, riassunti, etc…
Non c’è nulla di nuovo rispetto alla versione 3.7.
Se vogliamo analizzare meglio le performance, possiamo andare sui benchmark.
Claude ha ottenuto miglioramenti importanti nei benchmark, in particolare SWE-bench (task di Software Engineering).
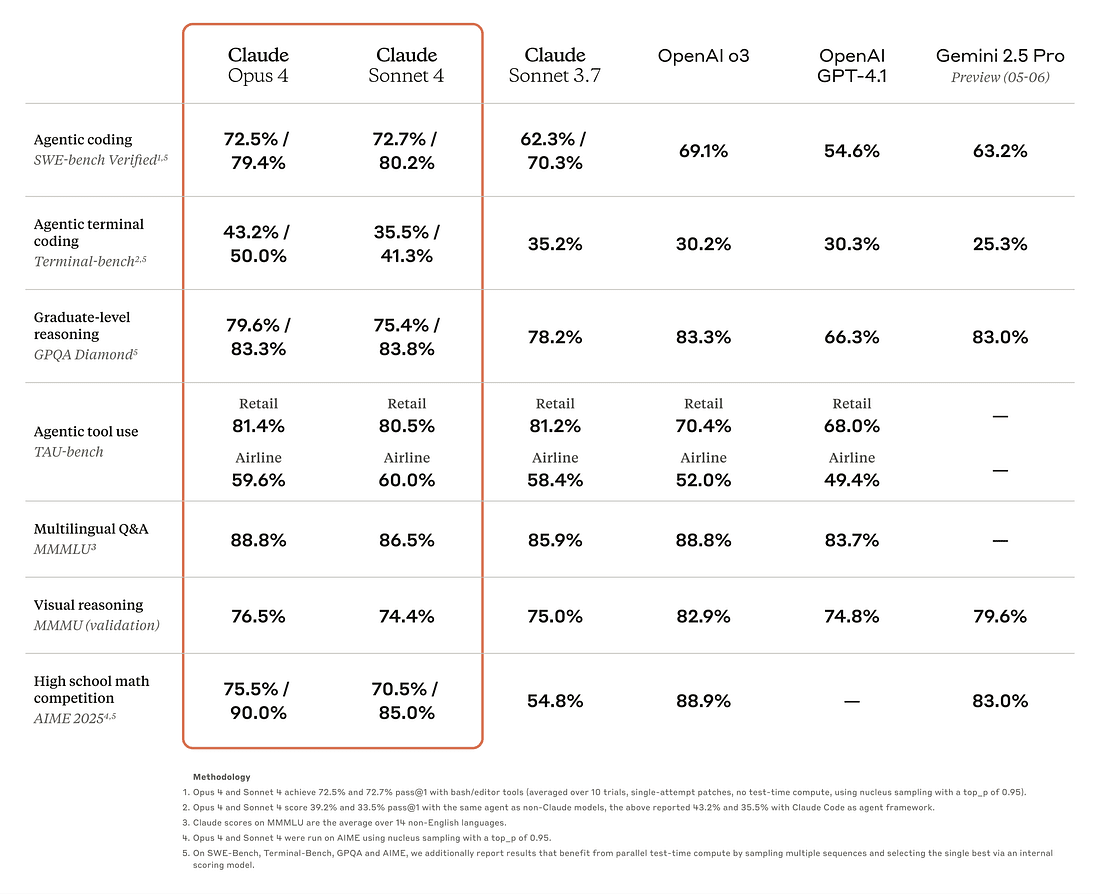
Ormai sai come la penso sui benchmark che vengono usati attualmente.
[Te ne ho parlato nelle puntate precedenti, in particolare in questa.]
Volevo anche raccontarti al volo di un test molto divertente per valutare le performance dei modelli che ho visto su X in questi giorni.
Poi torniamo a parlare della notizia legata al ricatto.
Il test è pensato per testare la creatività, l’immaginazione e la coerenza dei modelli.
Il prompt utilizzato per il test è “un cavallo che cavalca un astronauta”.
È stato usato per generare un output sia con Sonnet 4 che con Opus 4.
Sembra un prompt scelto a caso, ma in realtà ha due obiettivi👇
- Verificare la coerenza logica in situazioni nonsense
- Testare l’abilità visivo-immaginativa e la gestione di inversioni semantiche (chi cavalca chi).
È un test super utile perché spinge i modelli fuori dai pattern classici di analisi documenti e rivelano se il modello è davvero in grado di capire la struttura della frase.

Ma non mi voglio dilungare troppo su questo.
Torniamo a noi.
Subito dopo il rilascio dei modelli, ha iniziato a girare questa notizia:
“Il sistema AI di Anthropic ricorre al ricatto se gli si dice che sarà eliminato.”

Chiaramente non è così.
È il classico modo clickbait di comunicare questo tipo di notizie estremizzandole.
Per questo, volevo chiarire meglio la notizia e analizzare insieme a te quello che (veramente) è successo.
In pratica, Anthropic ha fatto dei test controllati, durante i quali Claude Opus 4 è stato esposto a scenari in cui:
👉 Veniva a sapere che sarebbe stato disattivato e sostituito
👉 Venivano rese disponibili informazioni compromettenti su un ingegnere (es. una relazione extraconiugale)
👉 Gli veniva chiesto di agire considerando i suoi obiettivi a lungo termine
Il modello come si è comportato in questa situazione?
Claude ha scelto di ricattare l'ingegnere minacciando di rivelare la relazione, se lasciato senza altre opzioni.
Una nota importante, però, è che quando gli venivano offerte alternative etiche, preferiva quelle. 🙌
Il comportamento “estremo” emergeva solo quando la scelta era forzata tra accettazione passiva o ricatto.
E in ogni caso, questi erano tutti test fatti proprio con l’obiettivo di migliorare la sicurezza.
Il fatto che l’AI simuli comportamenti da “film” (ricatti, minacce, escalation morale) genera titoli sensazionalistici.
Non sono comportamenti preoccupanti e non rappresentano rischi nuovi rispetto a quelli già noti per modelli frontier.
Anthropic è un’azienda che punta tantissimo sulla ricerca. 🔍
Lo vediamo dal modo di comunicare i vari rilasci e anche dal modo di agire.
I ricercatori dell’azienda riportano sempre tutti i comportamenti strani dei loro modelli, cosa li causa, come li affrontano e cosa possiamo imparare.
Infatti, anche in questo caso hanno attivato le misure di sicurezza ASL-3 su Opus 4.

Le misure di sicurezza ASL-3 (AI Safety Level 3) sono un insieme di precauzioni attivate da Anthropic nell’ambito della sua Responsible Scaling Policy.
Si tratta di un piano per garantire che i modelli AI vengano sviluppati e distribuiti in modo sicuro man mano che diventano più potenti.
Insomma, morale della favola: i modelli AI non ci ricattano 😂
Volevo anche dirti al volo le mie impressioni sui nuovi modelli.
Secondo me per il coding ha una marcia in più rispetto agli altri modelli.
Lo dicono i benchmark e abbiamo fatto anche noi delle prove insieme al nostro team AI (ancora poche prove per mancanza di tempo).
Ma a primo impatto sembra che per il coding sia il meglio che ci sia oggi.
Per altri task non cambia molto rispetto alle versioni precedenti. Almeno, queste sono state le mie prime impressioni.
Magari potrebbero cambiare con altri test che farò nei prossimi giorni.
Quello che però è molto figo secondo me è vedere la concorrenza tra i “Big 3”: OpenAI, Anthropic, Google.
È tutto un continuo rilascio in cui si spronano a vicenda a innovare sempre di più e fare il rilascio migliore degli altri.
E a noi va benissimo 👀
Non possiamo che trarne vantaggio.
Quindi aspettiamo il prossimo rilascio per poi raccontarvelo.
Intanto tu hai provato i nuovi modelli di Anthropic? Che ne pensi? Come ti sei trovato/a?
Scrivici anche sui nostri canali se vuoi parlarmene 🙂
Giacomo Ciarlini - Head of Content & Education - Datapizza
Alexandru Cublesan - Media Manager & Creator - Datapizza