14/01/2026Cosa abbiamo imparato testando la Contextual Retrieval su diversi dataset
Indice
- Cos’è la Contextual Retrieval e quando usarla
- L’idea di Anthropic
- Che problema risolve
- Il nostro setup sperimentale
- Dataset di valutazione
- Implementazione della pipeline
- Metriche di valutazione
- Esperimento 1: Contextual Retrieval vs Base Retrieval
- Setup
- Risultati
- Considerazioni
- Esperimento 2: Aggiunta del Reranker
- Perché un reranker
- I reranker testati
- Risultati
- Considerazioni
- Conclusioni
- Cosa abbiamo capito
- Quando usare la Contextual Retrieval
- Prossimi passi
Cos'è la Contextual Retrieval e quando usarla
L'idea di Anthropic
A settembre 2024, Anthropic ha proposto la Contextual Retrieval, una tecnica per migliorare la qualità del retrieval nei sistemi RAG. L'idea alla base è affrontare un problema frequente: i chunk estratti da un documento spesso perdono informazioni contestuali importanti quando vengono isolati dal loro contesto originale.
Prendiamo un esempio pratico dal nostro dataset D&D. Una tabella di armi da guerra potrebbe essere divisa in più chunk, e uno di questi potrebbe contenere:
| Battleaxe | 1d8 Slashing | Versatile (1d10) | Topple | 4 lb. | 10 GP |
| Flail | 1d8 Bludgeoning | — | Sap | 2 lb. | 10 GP |
| Longsword | 1d8 Slashing | Versatile (1d10) | Sap | 3 lb. | 15 GP |
| Maul | 2d6 Bludgeoning | Heavy, Two-Handed | Topple | 10 lb. | 10 GP |
Questo chunk contiene le informazioni sulla maul, ma manca l’header che indica che stiamo parlando di Martial Melee Weapons (Armi da Guerra). Un sistema di retrieval basato su similarità semantica potrebbe non recuperare questo chunk quando un utente chiede “Quale arma da guerra infligge il maggior numero di danni?”.
La Contextual Retrieval risolve questo problema arricchendo ogni chunk con un breve contesto che lo colloca all'interno del documento di origine. Questo contesto è generato da un LLM che, avendo accesso sia al singolo chunk sia all'intero documento, è in grado di produrre una descrizione contestuale accurata. Il contesto viene quindi anteposto al chunk, e l'unità così formata viene trasformata in embedding. Approfondiremo questo processo più avanti nel blogpost.
Che problema risolve
La contextual retrieval è particolarmente utile quando:
- I documenti contengono riferimenti impliciti (pronomi, abbreviazioni, rimandi a sezioni precedenti o future)
- Il significato di un chunk dipende dalla sua posizione nel documento (manuali con sezioni tematiche, regolamenti con capitoli, cataloghi con categorie)
- Le query degli utenti sono specifiche ma i chunk contengono informazioni generiche
Anthropic riporta miglioramenti significativi nelle metriche di retrieval, specialmente quando combinata con altre tecniche come il reranking.
Perché rivisitarla oggi?
È passato più di un anno dalla pubblicazione di quel post, e ci siamo chiesti: la Contextual Retrieval è ancora una tecnica valida nel 2026?
Nel frattempo, l'ecosistema di modelli e tecniche si è evoluto significativamente. In particolare, i reranker hanno fatto passi da gigante: modelli come Cohere Rerank v4 Pro e i nuovi reranker open-source come quelli della famiglia Qwen 3 offrono performance notevolmente superiori rispetto a un anno fa.
Questo ci ha portato a una domanda interessante: come interagisce la Contextual Retrieval con i reranker di nuova generazione e con dei dataset sfidanti? L'arricchimento contestuale dei chunk offre ancora un vantaggio significativo? Abbiamo deciso di scoprirlo sperimentalmente.
Il nostro setup sperimentale
Dataset di valutazione
Per i nostri esperimenti abbiamo utilizzato:
- D&D SRD 5.2.1 - Il nostro dataset pubblico costruito nel precedente blogpost, disponibile su HuggingFace, costruito con il nostro rag-dataset-builder, disponbile su GitHub. Contiene 56 domande (25 easy, 31 medium) con ground truth per i chunk richiesti.
- Due dataset privati protetti da NDA, su domini completamente diversi, per validare la generalizzabilità dei risultati. Negli esperimenti ci riferiremo a questi due dataset come dataset privato 1 e dataset privato 2.
Come spiegato nel blogpost precedente, la struttura char-based del nostro dataset ci permette di calcolare con precisione quali chunk sono necessari per rispondere a ogni domanda, indipendentemente dalla strategia di chunking adottata.
Implementazione della nostra pipeline di Contextual Retrieval
La Contextual Retrieval richiede un intervento nella fase di ingestion: prima di inserire i chunk nel vector store, è necessario arricchirli con informazioni contestuali che li situano all'interno del documento originale. Solo così l'embedding può catturare sia il contenuto del chunk che il suo contesto più ampio.
Per implementare questa ingestion abbiamo sfruttato l’IngestionPipeline di Datapizza AI. Questa architettura modulare ci permette di comporre diversi step di processing come componenti indipendenti: chunking, contestualizzazione, embedding e upsert su vector store. Abbiamo esteso la pipeline con componenti custom per la generazione del contesto tramite LLM.
Preprocessing
La pipeline del nostro esperimento dà per scontato che i documenti di input siano già stati convertiti in markdown. Per la conversione da PDF a markdown, rimandiamo al preprocessing del nostro rag-dataset-builder.
Chunking
Per il nostro dataset D&D SRD, per mantenere l’esperimento il più semplice possibile, abbiamo adottato un chunking by character con:
- Chunk size: 4000 caratteri
- Overlap: 100 caratteri
Contestualizzazione
Lo step di contestualizzazione è il cuore della Contextual Retrieval. Per ogni chunk, forniamo a un LLM:
- L’intero documento di appartenenza
- Il chunk da contestualizzare
L’LLM genera un breve contesto che viene poi anteposto al chunk nel formato:
CONTEXT: [contesto generato]
CONTENT: [testo originale del chunk]
Per generare il contesto, il prompt di Anthropic (dal blog post originale) è:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within
the overall document for the purposes of improving search retrieval
of the chunk. Answer only with the succinct context and nothing else.
Il nostro setup differisce in alcuni aspetti:
- Modello: Abbiamo usato Gemini 2.5 Flash come generatore di contesti, per bilanciare qualità e costi.
- Batching: Per ridurre i costi, contestualizziamo 10 chunk per chiamata invece di uno alla volta. Questo richiede un output strutturato che mappi ogni chunk al suo contesto.
- Prompt custom per dominio: Abbiamo creato prompt template specifici per ogni dataset. Per il nostro dataset D&D SRD, ad esempio:
<document>
{{ whole_document }}
</document>
You are an expert on the Dungeons & Dragons 5.2.1 System Reference Document.
Your task is to contextualize text chunks for improved semantic search retrieval.
## Key D&D 5th edition Concepts
- **Core Rules:** Ability Checks, Saving Throws, Attack Rolls, Combat Actions,
Conditions, Advantage/Disadvantage, modes of play.
- **Character Options:** Races/Species, Backgrounds, Classes, Subclasses,
Feats, Spells, Equipment.
- **Dungeon Master Content:** Monsters, NPCs, Traps, Hazards, Magic Items.
- **Lore & Setting:** Descriptions of the multiverse, planes, deities, factions.
## Your Task
For each chunk below:
1. Identify its primary category (e.g., "Fighter Class Feature", "Wizard Spell")
2. Extract key distinguishing attributes from the document that may not be
in the chunk itself (level, rarity, components, prerequisites, etc.)
3. Write a single paragraph of context focused on helping a user searching
for this rule or item.
{% for chunk in chunks %}
<chunk id="{{ chunk.id }}">
{{ chunk.text }}
</chunk>
{% endfor %}
Questi prompt domain-specific permettono all’LLM di generare contesti più accurati e rilevanti per il dominio.
Applicando la contestualizzazione all'intero dataset D&D SRD, e sfruttando il batching insieme a Gemini Flash 2.5, il costo totale si è attestato intorno ai 0,63$.
Embedding
I chunk (contestualizzati o meno) vengono poi embeddati usando Cohere embed-v4.0 (1536 dimensioni).
Caricamento su Qdrant
Una volta embeddati, i chunk vengono caricati su un vector database, nel nostro caso abbiamo scelto Qdrant. Ogni chunk viene salvato con:
- Il vettore dell’embedding (che contiene contesto e contenuto del chunk)
- Il testo originale (con e senza contesto)
- Metadati aggiuntivi (documento di origine, start char, end char, etc.)
Pipeline di confronto
Per i nostri esperimenti, abbiamo messo in piedi due pipeline parallele:
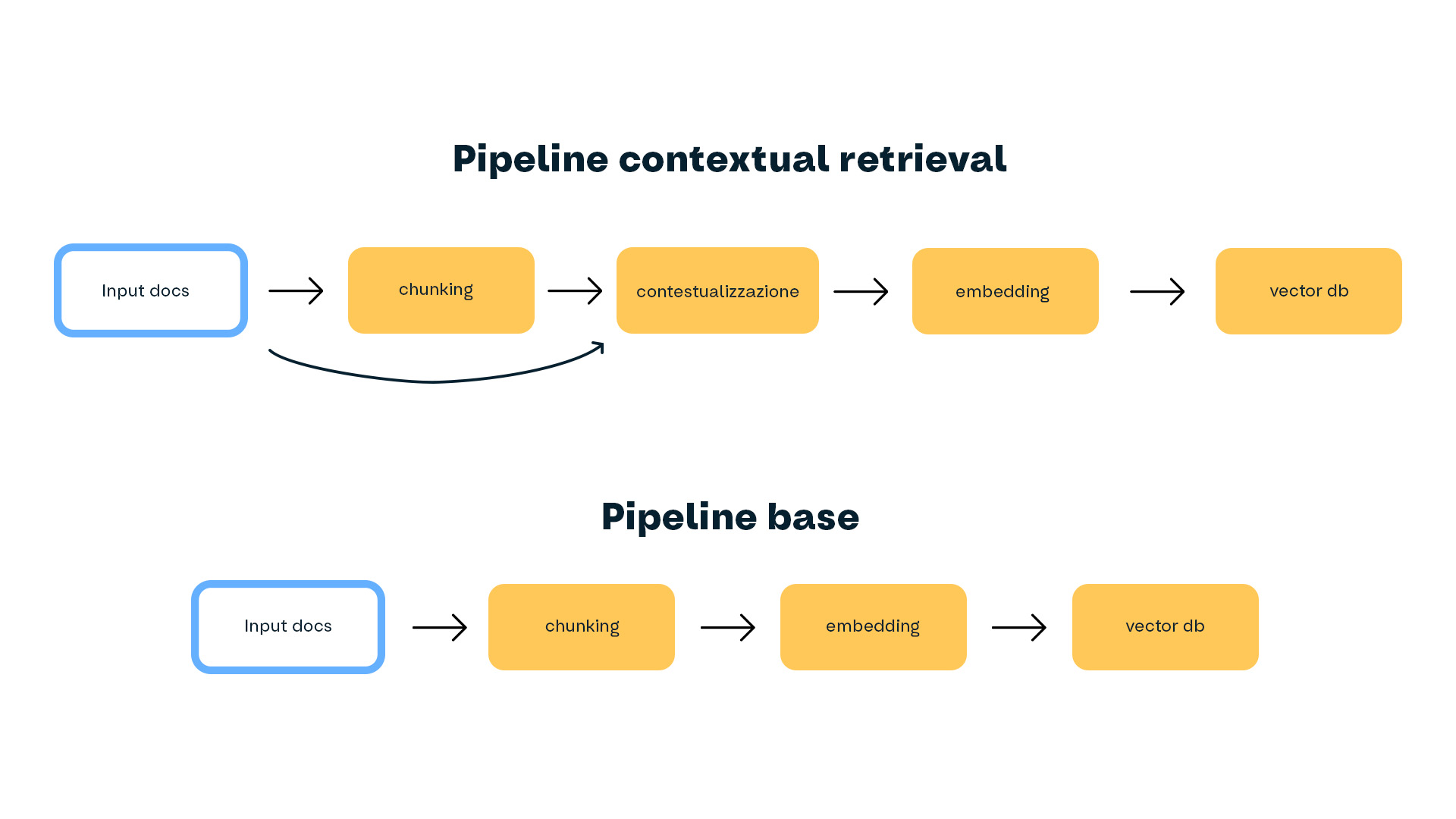

L’unica differenza è lo step di contestualizzazione, così da poter confrontare i due approcci e isolare il suo impatto sulle performance.
Metriche di valutazione: Recall
Per valutare la qualità del retrieval abbiamo utilizzato la metrica di recall.
La recall, in questo caso, corrisponde alla frazione dei chunk necessari per rispondere alla query effettivamente recuperati. Se una domanda necessita di 4 chunk e ne recuperiamo 3, la recall è 0.75.
Successivamente, per definire una singola metrica per un intero dataset, calcoliamo la recall media su tutte le domande del dataset fissando uno specifico valore di k, cioè il numero di chunk che il sistema recupera per ogni query. Ad esempio, con k=10 il sistema restituisce i 10 chunk più rilevanti secondo il modello di retrieval, e valutiamo quanti di questi sono effettivamente necessari per rispondere alla domanda. In questo modo otteniamo una metrica generale riassuntiva della performance del sistema.
Esperimento 1: Contextual Retrieval vs Base Retrieval
Setup
Il primo esperimento confronta direttamente la retrieval base con la contextual retrieval, senza reranker. Abbiamo valutato con k = 5, 10, 20.
L’embedding è stato generato usando Cohere embed-v4.0 (1536 dimensioni), e il retrieval avviene tramite similarity search su Qdrant.
Risultati
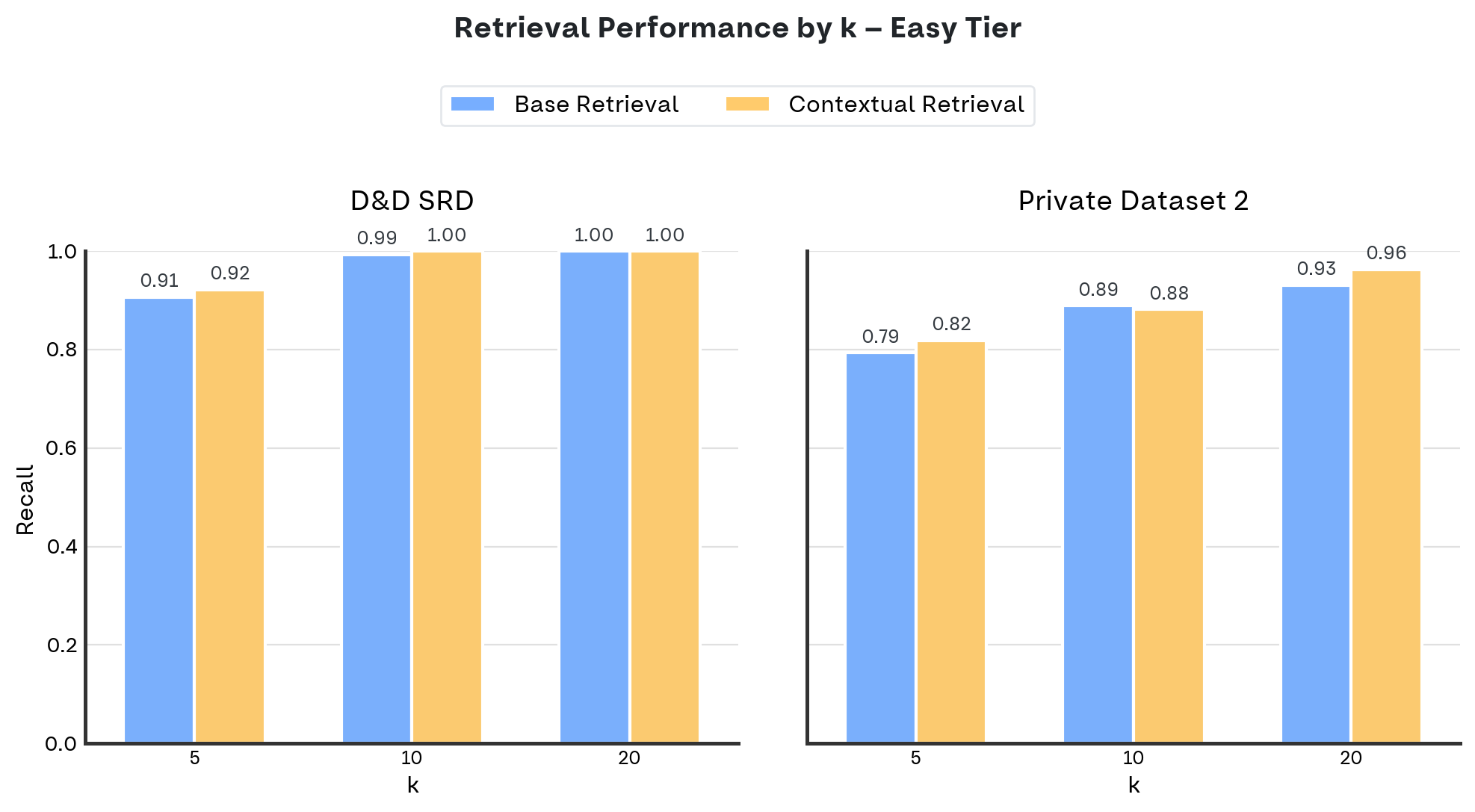
I grafici mostrano la recall (asse y) al variare di k = 5, 10, 20 (asse x), confrontando la base retrieval con la contextual retrieval.
Per le domande easy, abbiamo risultati su due dataset: D&D SRD e Private Dataset 2. Il Private Dataset 1 non include un set di domande easy.
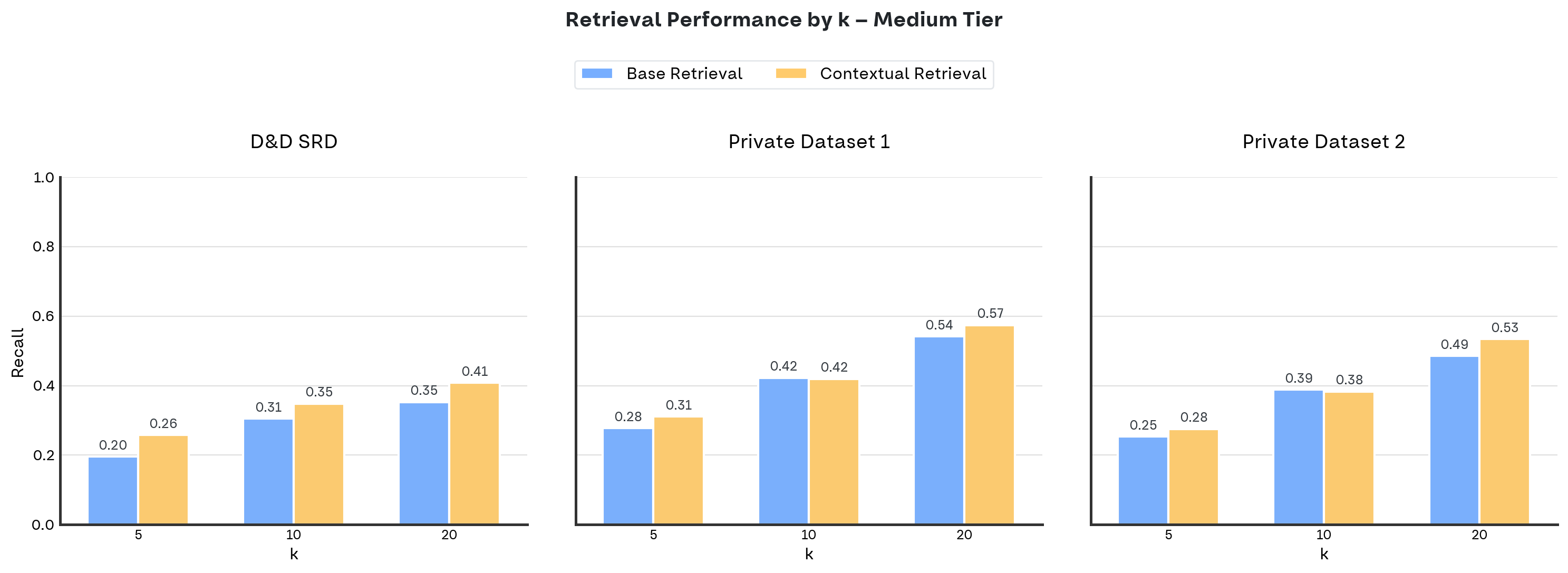
Per le domande medium, abbiamo risultati su tutti e tre i dataset: D&D SRD, Private Dataset 1, e Private Dataset 2.
Ogni grafico mostra un subplot per dataset, permettendo un confronto diretto tra i due metodi di retrieval.
La tabella seguente riporta il guadagno percentuale in recall della contextual retrieval rispetto all'approccio base (calcolato come recall_contextual − recall_base) per diversi valori di k:
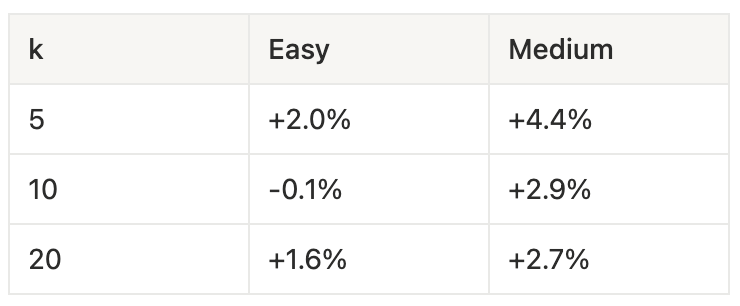
Un dato interessante emerge da questi risultati: il miglioramento maggiore si registra per k=5, mentre per k=10 il guadagno è minimo o addirittura leggermente negativo.
Una possibile spiegazione è che la contextual retrieval aumenti il numero complessivo di chunk rilevanti per ciascuna query. Con un valore di k limitato a 10, alcuni di questi chunk utili potrebbero essere esclusi dal cutoff, riducendo così il vantaggio rispetto all'approccio base.
Per verificare questa ipotesi, abbiamo calcolato il guadagno medio di recall per ogni valore di k nell'intervallo [1, 20]:
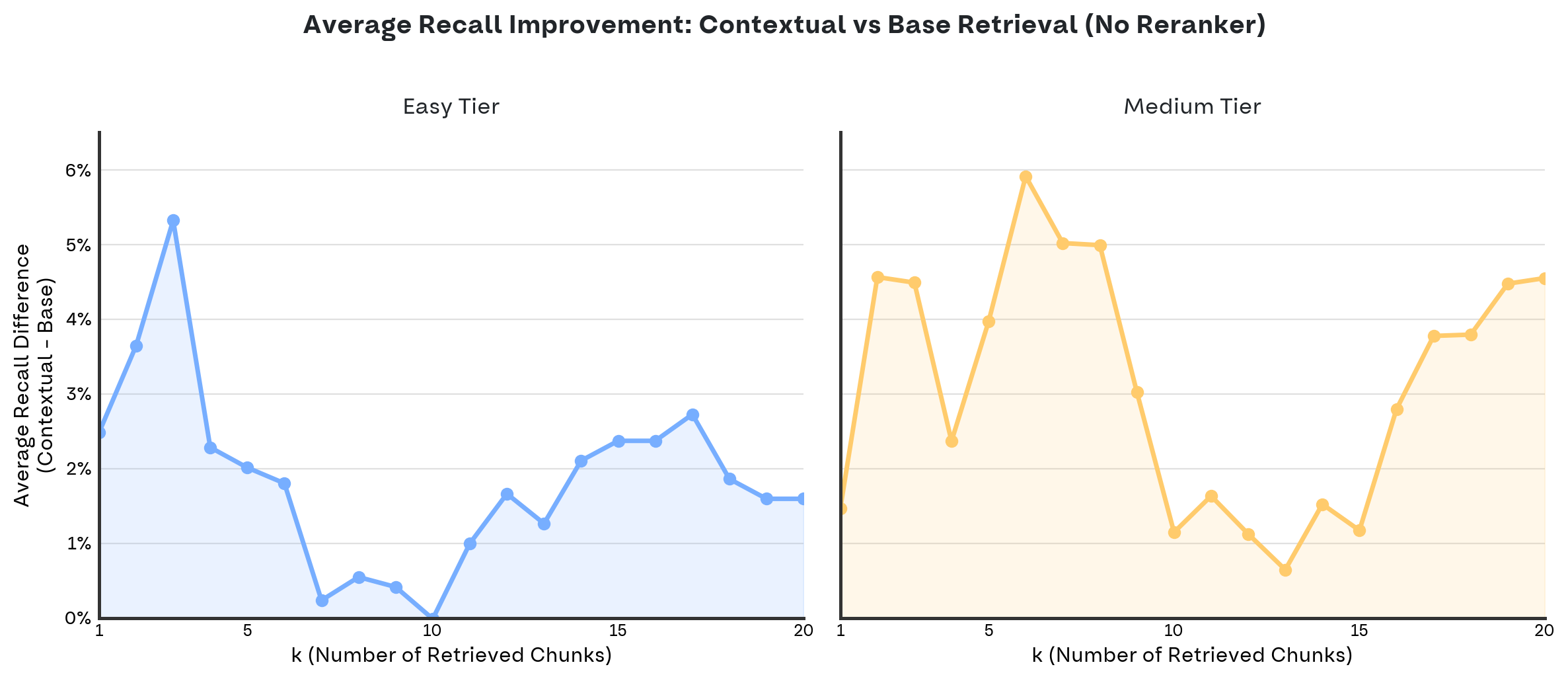
Il grafico conferma l'osservazione iniziale: sia per il tier Easy che per Medium, il guadagno raggiunge il minimo intorno a k=10, mentre risulta massimo per valori bassi di k. Questo comportamento suggerisce che la contextual retrieval sia particolarmente efficace nel posizionare i chunk più rilevanti nelle prime posizioni del ranking.
Considerazioni
- Miglioramento consistente: La contextual retrieval supera la base retrieval nella quasi totalità dei casi testati. Solo in rari casi i due approcci ottengono risultati equivalenti o la contextual mostra un lieve svantaggio.
- Domande easy vs medium: Sulle domande easy il miglioramento è modesto perché la base retrieval già performa molto bene, raggiungendo in diversi casi una recall del 100%, saturando la performance. Sulle domande medium, dove le domande sono più sfidanti, il vantaggio della contextual diventa più marcato.
- Impatto del valore di k: All'aumentare di k, entrambi gli approcci migliorano, ma la contextual retrieval mantiene il vantaggio. Il guadagno relativo tende a essere massimo per k bassi, confermando che la contextual retrieval sia particolarmente efficace nel posizionare i chunk più rilevanti nelle prime posizioni del ranking, ma porta ad un minimo intorno a k=10, suggerendo che aggiunga del rumore che tende a diventare preponderante intorno ai 10 chunk recuperati.
Esperimento 2: Aggiunta del Reranker
Perché un reranker
Abbiamo deciso di aggiungere un reranker alla pipeline per due motivi:
- Confronto equo con Anthropic: Nel loro blogpost originale, Anthropic utilizza un reranker. Volevamo essere corretti nel confronto e capire come la contextual retrieval interagisce con questa componente.
- Ipotesi: La nostra intuizione era che il contesto aggiunto potesse aiutare il reranker a discriminare meglio tra chunk rilevanti e non. Il reranker vedrebbe direttamente il testo e potrebbe sfruttare le informazioni contestuali.
Come funziona la pipeline con il reranker
Il flusso con reranker è:
- Retriever (similarity search): prende la query embeddata e recupera p chunk candidati
- Reranker: riceve la query come stringa + i p chunk, e produce uno score per ogni coppia query-chunk. Restituisce i q chunk con score più alto.
A differenza dell’embedder che opera su rappresentazioni vettoriali, il reranker analizza direttamente il testo, permettendo un matching più fine.
I reranker testati
Abbiamo testato due reranker:
- Cohere Rerank v4 Pro: l’ultimo reranker di punta di Cohere, rilasciato l’11 decembre 2025. Reranker stato dell’arte dall’ottima qualità.
- Qwen3 Reranker 8B: modello open-weight di Alibaba. Si tratta del modello base 8B fine-tunato per il rerank dei chunk. Per utilizzarlo abbiamo:
Questo setup ci permette di avere un reranker self-hosted con costi contenuti e senza dipendenza da API esterne.
- Deployato una macchina su Scaleway con GPU L4 (24GB VRAM)
- Avviato un container vLLM per servire il modello
- Connesso tramite OpenAI-compatible API usando Datapizza AI
Risultati
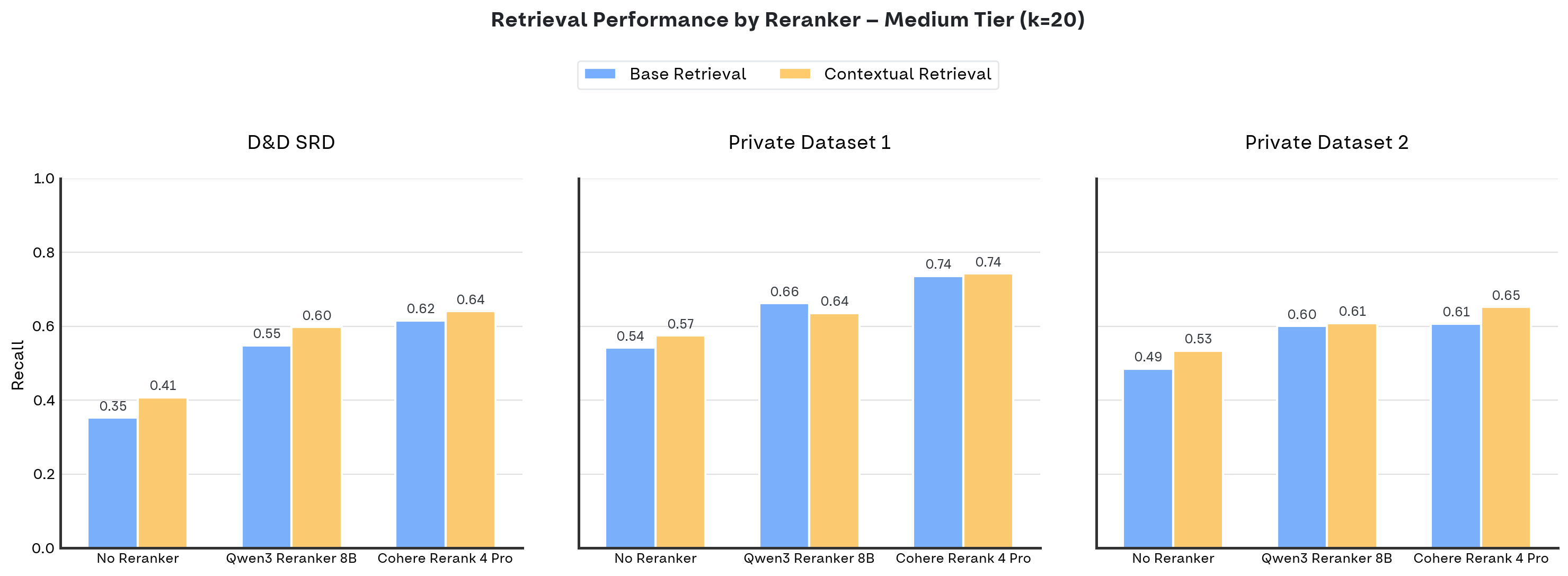
A seguito dei nostri esperimenti, qui sotto indichiamo tutti i risultati ottenuti di recall sulla difficoltà medium, con k fissato 20. Tutti i risultati dettagliati sono disponibili
Come ulteriore approfondimento, applichiamo la stessa metodologia dello step precedente (in cui non veniva utilizzato alcun reranker) per analizzare il miglioramento della recall introdotto dalla contextual retrieval rispetto all'approccio base (calcolato come recall_contextual − recall_base), esplorando l'intero intervallo k ∈ [1, 20].
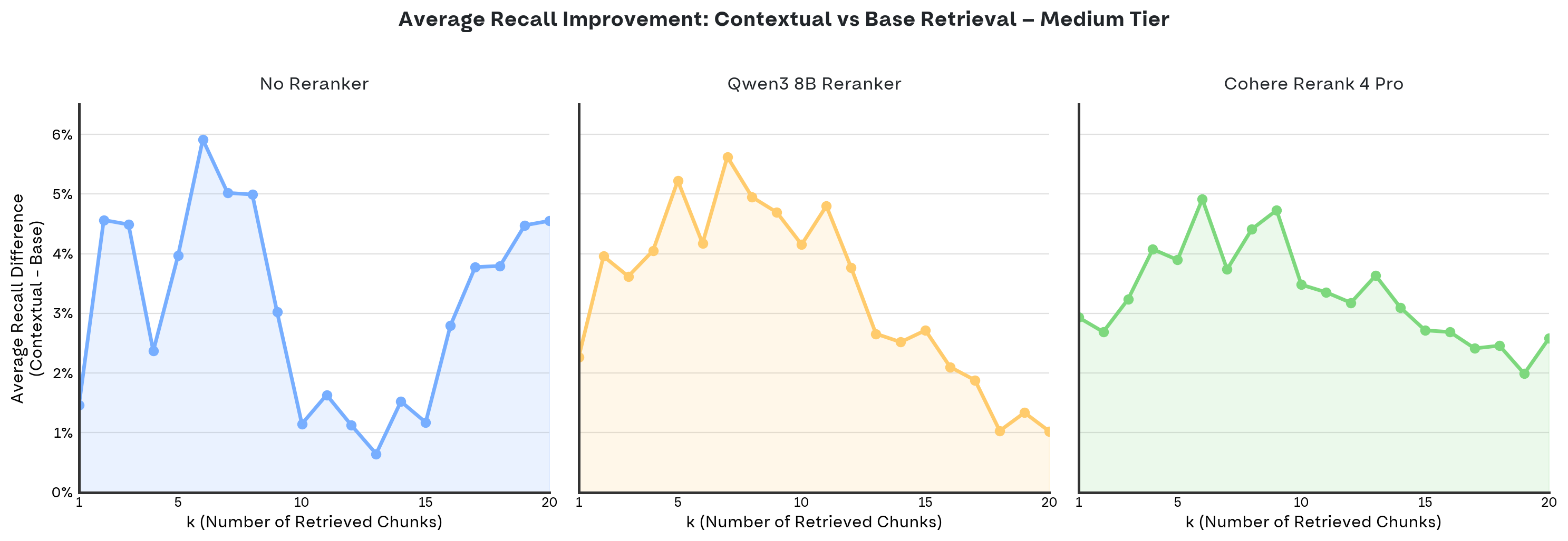
Con l'introduzione di un reranker, il minimo di guadagno osservato intorno a k=10 scompare. Si nota invece un picco di miglioramento intorno a k=5, seguito da un calo progressivo per valori superiori. Questo andamento suggerisce che, all'aumentare di k, lo spazio di miglioramento offerto dalla contextual retrieval si riduce gradualmente
Considerazioni
- Il reranker migliora entrambe le pipeline: Aggiungere un reranker porta miglioramenti significativi sia alla base che alla contextual retrieval.
- La contextual vince quasi sempre: Nonostante il gap ridotto, la contextual retrieval supera la base retrieval in quasi tutti gli scenari, anche con il reranker. L'unica eccezione riguarda il dataset 1 con Qwen3 Reranker 8B, un risultato prevedibile dato che questo dataset presenta una struttura confusa e un chunking subottimale. Si tratta quindi di un caso isolato, non di una tendenza generale.
- Maggiore stabilità al variare di k: Il reranker rende il guadagno più stabile al variare di k, eliminando la zona di minimo intorno a k=10. Questo evidenzia una buona sinergia tra contextual retrieval e reranker, che insieme riducono il rumore tra i chunk recuperati. I miglioramenti più marcati si concentrano comunque intorno a k=5, confermando che la contextual retrieval è particolarmente efficace nel posizionare i chunk rilevanti nelle prime posizioni del ranking. Al crescere di k invece, i risultati suggeriscono che parte del valore della contestualizzazione viene “assorbito” dal reranker.
Conclusioni
Cosa abbiamo capito
Dopo questi esperimenti, le nostre conclusioni sono:
- La Contextual Retrieval continua ad essere valida: In tutti i nostri test, su tre dataset diversi, la contestualizzazione ha sempre portato a un miglioramento delle performance.
- Il miglioramento è più marcato ma instabile senza reranker: Se la tua pipeline non usa un reranker, la contextual retrieval offre un boost significativo, specialmente per valori di k elevati. Con un reranker però, la qualità generale (anche nel caso base) migliora e i risultati tendono ad essere più stabili al variare di k, con un picco intorno a valori di k=5.
- Le domande difficili rimangono difficili: Anche con contestualizzazione e reranker, le domande del tier medium mettono comunque in difficoltà. C’è spazio per architetture più sofisticate.
Quando usare la Contextual Retrieval
Consigliamo la Contextual Retrieval quando:
- Puoi permetterti un’ingestion più costosa (nel nostro caso ~0,63$, siccome ogni chunk richiede una chiamata LLM)
- I tuoi documenti hanno molti riferimenti impliciti o informazioni contestuali
- Hai un dominio specifico per cui puoi creare prompt template ottimizzati
Potrebbe non valere la pena se:
- Hai vincoli stringenti sui costi di ingestion
- Il chunking della knowledge base non si presta allo step di contestualizzazione
- I tuoi chunk sono già molto espliciti e auto-contenuti
Prossimi passi
Ci sono diverse direzioni interessanti per esperimenti futuri:
- Hybrid Search: integrare BM25 o altri metodi di retrieval lessicale insieme alla similarity semantica
- Chunking strategies: valutare l’impatto di diverse strategie di chunking (semantic, sentence-based, LLM based ecc.)
- Diversi template di contestualizzazione: confrontare prompt template differenti per la generazione del contesto
- Contextual Retrieval multimodale: estendere lo step di contestualizzazione per poter funzionare con altri tipi di input, come le immagini
- Batch size della contestualizzazione: aumentare la batch size oltre 10 e valutare in modo strutturato il tradeoff tra costo (numero di token) e qualità della contestualizzazione generata
Il codice completo con cui abbiamo condotto questi esperimenti è disponibile nella nostra repository GitHub.
Raul Singh - GitHub - LinkedIn - AI R&D Engineer - Datapizza
Ling Xuan “Emma” Chen - GitHub - LinkedIn - AI R&D Engineer - Datapizza
Francesco Foresi - GitHub - LinkedIn - GenAI R&D Team Lead - Datapizza