10/09/2025OpenAI ha la soluzione: l’AI smetterà di inventare cose?
OpenAI ha pubblicato un nuovo paper in cui spiega perché i modelli di linguaggio allucinano.

Ma prima di addentrarmi nel tema, volevo fare un passo indietro e chiarire alcuni concetti.
Partiamo dalle basi: cosa sono le allucinazioni?
Quando i modelli AI non sanno la risposta, “inventano cose” che sembrano corrette ma in realtà sono false o inesatte.
E c’è da dire che questo aspetto è migliorato molto nel tempo! 🙌
Se pensiamo a GPT-2, GPT-3 etc… allucinavano molto, spesso anche in modo evidente.
Oggi, con modelli come GPT-5 o Claude 4, le allucinazioni sono meno frequenti e meno evidenti, ma non sparite del tutto.
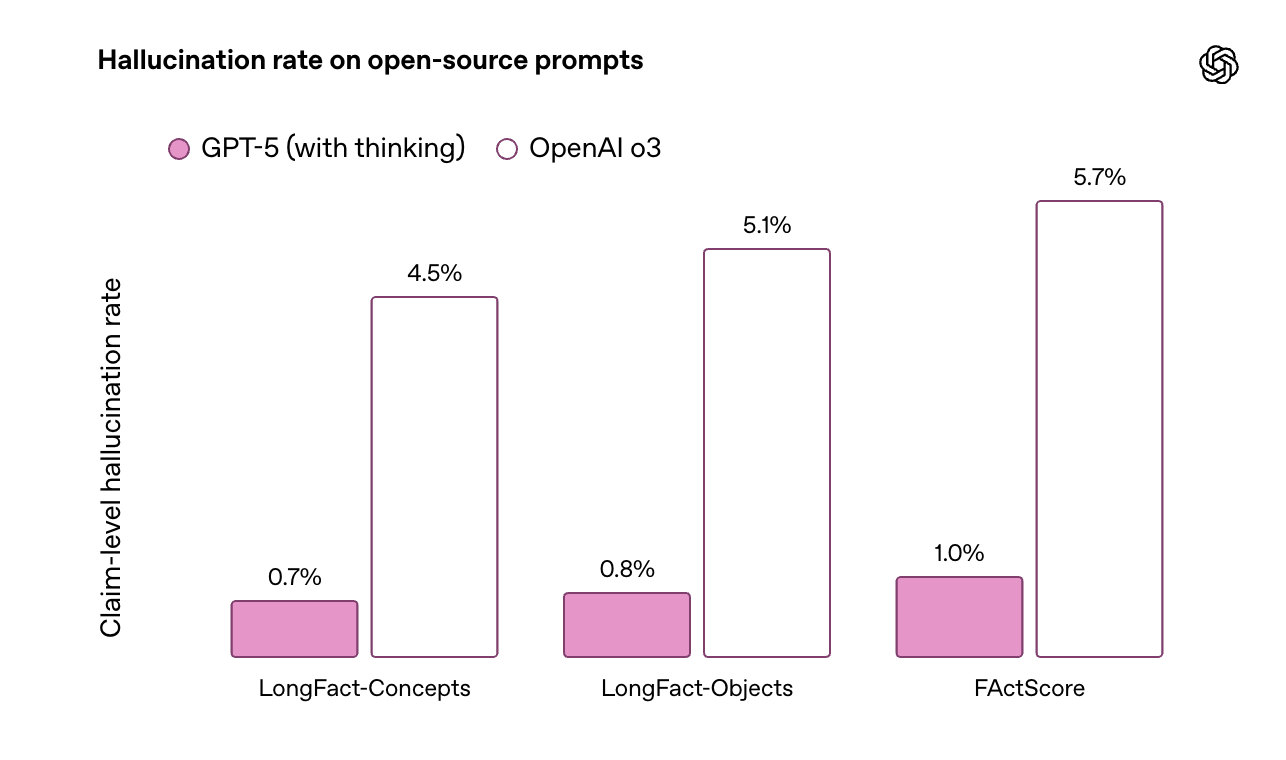
Possono ancora dare risposte sicure ma errate, soprattutto su dettagli specifici o informazioni recenti.
Di base, la tendenza nel tempo è stata che ogni generazione di modelli riduceva “un po’” il tasso di allucinazioni, ma resta comunque un problema aperto.
Con questo paper, OpenAI spiega perché accadono, suggerendo anche delle soluzioni.
La risposta breve sarebbe che i modelli allucinano perché il training e la ricompensa premiano il "tirare a indovinare" invece di ammettere l'incertezza.
Magari non è ancora chiaro cosa si intende, adesso andiamo più nello specifico 🙂
Ti faccio un esempio.
Pensa ad uno studente che si trova a dare un’esame all’università. 📚
Sa che rispondere “non lo so” vale zero punti, mentre tentare una risposta a caso può valerne uno.
E quindi che cosa fa?
Esatto, tira a caso.
Torniamo più nel tecnico.
Quando si addestra un modello, viene valutato con sistemi binari:
📌 giusto = 1 punto
📌 sbagliato o "non so" = 0 punti
Questo crea un incentivo statistico sbilanciato.
Meglio inventarsi una risposta specifica che magari a volte azzecca, piuttosto che ammettere di non sapere.
La soluzione proposta da OpenAI è di cambiare il sistema di valutazione: premiare l’incertezza appropriata e penalizzare di più gli "errori sicuri".
E i loro test mostrano come lasciare che il modello ammetta di non sapere riduca tantissimo le allucinazioni.
Ma nonostante ciò, alcuni errori sono inevitabili…
I modelli di linguaggio imparano meglio i compiti che hanno regole chiare e ripetitive, mentre fanno molta più fatica con quelli che dipendono solo dalla memoria di fatti isolati.
Nel paper, i ricercatori distinguono tre tipi di compiti:

1️⃣ Spelling e regole chiare: le regole sono fisse e generalizzabili.
Se impari l’alfabeto e la sequenza di lettere, puoi applicarle a qualsiasi parola.
Per questo i modelli sono ottimi nello spelling o nelle regole grammaticali.
2️⃣ Conteggio: non è così rigido come lo spelling, qui c’è logica, ma i pattern non sono sempre lineari.
I modelli possono “indovinare” basandosi su regolarità statistiche, ma con errori frequenti.
3️⃣ Date di nascita (o fatti puntuali): qui non c’è un pattern da imparare.
La data di nascita di Einstein non si ricava da regole statistiche, è un fatto unico che o lo hai memorizzato nei dati di training o no.
Se manca, il modello non ha scelta: tira a caso.
Quindi che cosa cambia con il rilascio di questo paper? 🤔
Per il momento nulla per noi che utilizziamo questi modelli nella nostra quotidianità.
Ma è un’ottima base di partenza perché hanno formalizzato alcune intuizioni che probabilmente daranno risultati nei prossimi modelli.
La cosa è molto semplice, è probabile che future versioni dei modelli saranno più affidabili semplicemente perché risponderanno più spesso "non lo so".
E se ci pensi è molto meglio!
Perché puoi approfondire tu quel dettaglio specifico piuttosto che rischiare di utilizzare un’informazione sbagliata.
Quello che puoi fare oggi è non fidarti al 100% delle risposte super specifiche su fatti poco comuni.
O meglio, dipende per che cosa usi l’AI:
-Se usi ChatGPT per fare brainstorming creativo, l’allucinazione è “meno grave”
-Se lo usi per dati precisi, diventa già più rischiosa
Non è di tanto tempo fa il caso dell’avvocato che a Firenze usò ChatGPT per un processo e il chatbot si inventò le sentenze della Cassazione. 😅
Insomma, per chiudere, diciamo che questo paper dà una direzione di ricerca chiara, anche se non è detto che la soluzione finale sia questa.
Ma è sicuramente un primo passo verso modelli più affidabili. 🙌
Giacomo Ciarlini - Head of Content & Education - Datapizza
Alexandru Cublesan - Media Manager & Creator - Datapizza